Redefining Imports in Python using Pyforest : Accelerate ML & Data Science development

I'm a science guy with a creative instinct. Simple-minded & doing what I'm good at & sharing what I've learnt so far with amazing people like you'll.
Hi and Welcome
Most Data Science, Machine learning projects start with importing endless number of modules and packages, Writing the same imports over and over again is below your capacity. There are several problems with this. Admittedly, they are small but they add up over time.
Missing imports disrupt the natural flow of your work. Sometimes, you may even need to look up the exact import statements, like import matplotlib.pyplot as plt or from sklearn.ensemble import GradientBoostingRegressor.
What if you could just focus on using the libraries?
Content Overview :
Before we start let's have a quick look at the beautiful mess :
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import sklearn
from sklearn.preprocessing import OneHotEncoder
from sklearn.manifold import TSNE
from sklearn.cross_validation import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
import sys
import os
import re
import glob
from pathlib import Path
import pickle
import datetime as dt
All of these & more can be imported using just one line :
from pyforest import *
What is pyforest
- Pyforest is the lazy imports of all popular python Data Science libraries so that they are always in there in your work environment, when you need them, this is also known as lazy import in python.
- If you don’t use a library or any of it’s method or function, it won’t be imported . When you are done with your script, you can export the python code for the imported statements for the later use.
Installing pyforest
From the terminal (or Anaconda prompt), enter:
pip install pyforest
OR
Install directly into the jupyter / google colab notebook :
! pip install pyforest
Use
!to run bash commands.
Using pyforest
First Import pyforest
from pyforest import *
You can see an overview of all available lazy imports if you just type lazy_imports() in Python.
lazy_imports()
Output:
['import numpy as np',
'import tensorflow as tf',
'import plotly.express as px',
'from sklearn.ensemble import GradientBoostingClassifier',
'import nltk',
'import pandas as pd',
'import plotly as py',
'import statistics',
'from sklearn.ensemble import GradientBoostingRegressor',
'import os',
.
.
.
]
# In total there are 40 modules, I've displayed only a few for convenience
When you are done with your script, you can export all import statements via:
active_imports()
Output:
import numpy as np
import tensorflow as tf
import pandas as pd
import plotly as py
['import numpy as np',
'import tensorflow as tf',
'import pandas as pd',
'import plotly as py']
Why is the project called pyforest? pyforest is created to be the home for all Data Science packages - including pandas. And in which ecosystems do pandas live?
Understanding with simple python code
from pyforest import *
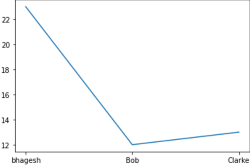
data = [['bhagesh',23],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'])
print(df)
output:
Name Age
0 bhagesh 23
1 Bob 12
2 Clarke 13
plt.plot(df.Name,df.Age)
output:
[<matplotlib.lines.Line2D at 0x7f0cb666b748>]
active_imports()
Output:
import matplotlib.pyplot as plt
import pandas as pd
[ 'import matplotlib.pyplot as plt',
'import pandas as pd']
I Love pyforest & I know you will too...
If you have made it so far, you're Awesome; hope this helps you in your coding journey.
Read more articles by me here CodeBeast Support me by hitting the subscribe button on my YouTube channel CodeBeast



